발표 날짜 24.11.25 MON 10시a.m.
CH39 막간 - 파일과 디렉터리
운영체제를 구성하는 두 개의 핵심 개념은 CPU를 가상화한 "프로세스"와 메모리를 가상화한 "주소 공간"이다
이 개념들은 서로 협력하여 응용 프로그램들이 서로 독립된 세계에서, 자신만의 프로세서 또는 자신만의 메모리가 있는 것처럼 만들어 준다
하드 디스크 드라이브 또는 솔리드스테이트 드라이브 Solid-state storage, SSD 같은 영속 저장 장치 Persistent Storage 는 전원 공급이 차단되는 상황에서도 영구적으로 데이터를 그대로 보존할 수 있고, 운영체제는 그런 장치들을 좀 더 신중하게 다루어야 한다
핵심 질문 - 어떻게 영속 장치를 관리하는가
운영체제가 영속 장치를 어떻게 관리해야 할까? API들은 어떤 것이 있는가? 구현의 중요한 측면은 무엇인가?
39.1 파일과 디렉터리
1) 파일
단순히 읽거나 쓸 수 있는 순차적인 바이트의 배열
각 파일은 숫자로 표현된 저수준 이름 Low-level name 을 가지고 있고, 이 이름을 아이노드 번호 Inode Number 라고 부른다
사용자는 파일의 이름을 모른다, 각 파일은 아이노드 번호와 연결되어 있다고 이해하면 된다
대부분의 시스템에서 운영체제는 파일의 구조를 모르고, 파일 시스템이 그러한 데이터를 디스크에 저장하고, 데이터가 요청되면 처음 저장했던 데이터를 돌려주는 역할을 한다
파일의 이름이 bar.txt 일 때 첫번째 부분은 임의의 이름이고 두번째 부분은 대체적으로 파일의 종류를 나타내기 위해 사용된다
하지만 대부분 관용적 Convention 일 뿐, main.c 라고 해서 반드시 내용이 C 소스 코드일 필요는 없다
2) 디렉터리
디렉터리 이름은 <사용자가 읽을 수 있는 이름, 저수준의 이름> 쌍으로 이루어진 목록으로 구성된다
디렉터리의 각 항목은 파일 또는 다른 디렉터리를 가리킬 수 있고, 디렉터리 내에 다른 디렉터리를 포함하면
디렉터리 트리 Directroy Tree 또는 디렉터리 계층 Directory Hierarchy 을 구성할 수 있다
디렉터리 계층은 루트 디렉터리 Root Directory 부터 시작하여, 구분자 Separator 를 사용하여 하위 디렉터리를 명시할 수 있다
UNIX 기반의 시스템에서 루트 디렉터리는 / 으로 표현되어, /foo/bar.txt 와 같은 절대 경로명 Absolute Pathname 을 표현할 수 있다
디렉터리들과 파일들은 파일 시스템 트리 안에서 서로 다른 위치에 있다면 동일한 이름을 가질 수 있다
어떤 자원을 접근하는 가장 첫단계는 그 대상의 이름을 아는 것이기 때문에 시스템에서 이름 짓기 기능은 매우 중요하다
39.2 파일 시스템 인터페이스
파일 시스템 인퍼테이스를 좀 더 상세하게 다룰 예정이다, 파일 삭제를 담당하는 unlink() 라는 살짝 혼란스런 시스템 콜도 다룰 것이다
39.3 파일의 생성
open 시스템 콜을 호출하면서 O_CREAT 플래그를 전달하면 프로그램은 새로운 파일을 만들 수 있다
/* 현재의 디렉터리에 "foo" 라는 파일을 만드는 코드 */
int fd = open("foo", O_CREAT | O_WRONLY | O_TRUNC, S_IRUSR | S_IWUSR);O_CREAT - 파일이 없으면 파일을 생성한다
O_WRONLY - 쓰기만 가능하다
O_TRUNC - 파일이 이미 존재하면 파일의 크기를 0 byte 로줄여서 기존 내용을 모두 삭제한다
S_IRUSR | S_IWUSR - 권한 설정, 여기서는 파일의 소유자만 해당 파일을 읽고 쓸 수 있도록 설정
open() 에서 제일 중요한 항목은 리턴값이다: 파일 디스크립터 File Descriptor
파일 디스크립터는 프로세스마다 존재하는 정수로서, UNIX 시스템에서 파일을 접근하고, 읽고 쓰는 데에 사용된다
물론 해당 파일에 대한 권한을 갖고 있어야 한다
파일 디스크립터는 기능 Capability 이자, 특정 동작에 대한 수행 자격을 부여하는 핸들이고, 파일 개체를 가리키는 포인터로 볼 수도 있다
39.4 파일의 읽기와 쓰기
아래 코드는 echo 의 출력을 파일 foo 로 전송 redirect 하여 그 파일에 "hello" 를 저장하도록 하고, cat 으로 파일 내용을 확인하였다
prompt> echo hello > foo
prompt> cat foo
hello
prompt>cat 프로그램은 어떻게 파일 foo 에 접근할까?
프로그램이 호출하는 시스템 콜을 추적하는 도구 strace (Linux)/ dtruss (Mac OS X)/ truss (UNIX) 를 살펴본다
strace 가 하는 일은 프로그램이 실행되는 동안에 호출된 모든 시스템 콜을 추적하고, 그 결과를 화면에 보여준다
/* strace 를 이용해서 cat 동작 알아보기 */
prompt> strace cat foo
...
open("foo", O_RDONLY | O_LARGEFILE) = 3
read(3, "hello\n", 4096) = 6
write(1, "hello\n", 6) = 6
hello
read(3, "", 4096) = 0
close(3) = 0
...
prompt>1) 파일 열기 - 읽기만 가능한 상태로, 64 bit 오프셋이 사용되도록 설정하여 파일을 열고, 열기에 성공하면 3을 리턴한다
기본 파일 디스크립터가 [0 표준 입력, 1 표준 출력, 2 표준 에러] 이기 때문에, 다음 파일 디스크립터는 3이 되기 때문에 3을 리턴
2) read() 시스템 콜을 사용하여 파일에서 몇 바이트씩 반복적으로 읽기 - 첫번째 인자는 파일 디스크립터, 두번째 인자는 read() 결과를 저장할 버퍼, 세번째 인자는 버퍼의 크기를 나타낸다, 버퍼의 크기는 read() 가 성공적으로 리턴하며 읽은 바이트 수를 나타낸다
3) write() 시스템 콜을 사용하여 화면에 글자 출력하기 - 파일 디스크립터 1 (표준 출력 STDOUT) 을 사용한다
cat 프로그램이 write() 를 직접 호출할 수도 있지만, 그렇지 않다면 라이브러리 루틴인 printf() 를 호출할 수도 있다
내부적으로 printf() 는 전달 받은 문자열에 적절한 포멧을 적용한 후, 결과를 표준 출력에 써서 화면에 출력한다
4) read() 시스템 콜로 파일의 내용을 더 읽으려고 시도 - 파일에 남은 바이트가 없기 때문에 read() 는 0을 리턴한다
5) close() 를 호출하여 "foo" 라는 파일에서 할 일이 끝났음을 표시 - 파일은 닫히고 읽기 작업은 완료된다
파일을 쓰는 단계도 비슷하다, 1) 파일을 쓰기 위해 열고 2) write() 시스템을 호출한다 - 파일이 큰 경우 write() 시스템 콜을 반복적으로 호출할 수 있다 3) close() 를 호출하여 파일을 닫는다
🐣 오프셋 비트가 늘어나면 좀 더 정밀하게 위치 이동이 가능하다, 그래서 데이터를 블럭 단위로 접근할 수 있다 🐣
39.5 비순차적 읽기와 쓰기
지금까지의 파일 읽고 쓰는 과정은 모두 순차적이었지만, 때로는 파일의 특정 오프셋부터 읽거나 쓰는 것이 유용할 때가 있다
문서 내의 임의의 오프셋에서 읽기를 수행할 때 lseek() 라는 시스템 콜을 사용한다
off_t lseek(int fildes, off_t offset, int whence);첫번째 인자 - 파일 디스크립터
두번째 인자 - offset, 파일의 특정 위치 file offset 를 가리킨다
세번째 인자 - 탐색 방식을 결정한다
whence 가 SEEK_SET 이면, 오프셋은 offset 바이트로 설정된다
whence 가 SEEK_CUR 이면, 오프셋은 현재 위치에 offset 바이트를 더한 값으로 설정된다
whence 가 SEEK_END 이면, 오프셋은 파일의 크기에 offset 바이트를 더한 값으로 설정된다
운영체제는 프로세스가 open() 한 각 파일에 대해 "현재" 오프셋을 추적하여 다음 읽기 또는 쓰기 위치를 결정한다
오프셋은 두 가지 중 하나의 방법으로 갱신된다 1) N 바이트를 읽거나 쓸 때 현재 오프셋에 N 이 더해진다 - 각 읽기 또는 쓰기는 암묵적으로 오프셋을 갱신한다 2) lseek 로 명시적으로 오프셋을 변경한다
39.6 공유하는 파일 테이블의 요소들 - fork() 와 dup()
열린 파일 테이블의 요소와 파일 디스크립터를 연결하는 것은 일대일 매핑으로 이루어진다
어떤 다른 프로세스가 같은 파일을 동시에 읽는다 하더라도 각 프로세스는 개별적인 열린 파일 테이블의 요소를 다룬다
프로세스들이 열린 파일 테이블을 공유하는 경우가 있는데, 부모 프로세스가 fork() 를 사용하여 자식 프로세스를 생성하는 것이 그런 경우 중 하나이다, 자식 프로세스는 현재 오프셋을 lseek() 를 사용하여 조정한 후 종료하고, 자식이 종료되길 기다렸던 부모는 현재 오프셋을 확인한 후 그 값을 출력한다
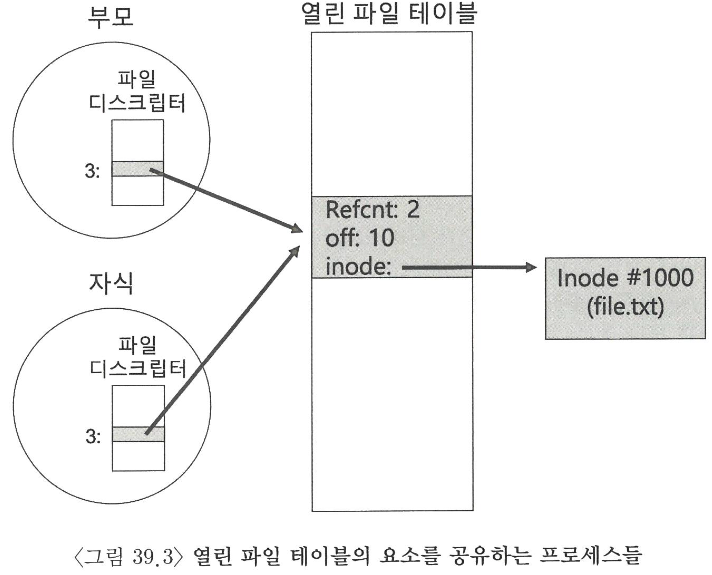
위 그림은 각 프로세스가 관리하는 디스크립터 배열, 열린 파일 테이블의 요소, 파일 시스템 아이노드에 대한 참조 간의 관계를 나타낸다
여기서 파일 테이블의 요소가 공유되면 참조 횟수 Reference Count 가 증가된다, 두 프로세스가 모두 파일을 닫은 (또는 종료) 후에 이 요소는 제거된다
🐣 fork() 를 사용하면 부모의 파일 디스크립터가 복제되고, 부모와 자식은 같은 열린 파일 테이블을 공유한다,
그래서 열린 파일 테이블을 같이 공유할 수 있는 것이다 🐣
dup() 시스템 콜은 이미 열려 있는 파일의 디스크립터를 참조하는 새로운 파일 디스크립터를 생성한다, dup() 호출은 유닉스 쉘과 출력 재지향을 하는 코드를 작성하는데 유익하다
39.7 fsync() 를 이용한 즉시 기록
write() 호출의 목적은 대부분 해당 데이터를 가까운 미래에 영속 저장 장치에 기록해 달라고 파일 시스템에게 요청하는 것이다
응용 프로그램의 입장에서는 write() 호출 즉시 쓰기가 완료된 것처럼 보이지만, 성능 상 이유로 파일 시스템은 쓰기들을 일정 시간 동안 메모리에 모으고 (버퍼링) 일정 간격으로 쓰기 요청(들)을 저장 장치에 전달한다
드물게 write() 를 호출하였지만 디스크에 쓰기 직전에 기계가 크래시한 경우 같은 예외 상황에 데이터가 유실되는 상황이 발생한다
그렇기에 어떤 프로그램은 때때로 강제적으로 즉시 디스크에 기록할 수 있는 성능을 필요로 한다
UNIX 에서는 프로세스가 특정 파일 디스크립터에 대해서 fsync() 를 호출하면 파일 시스템은 지정된 파일의 모든 갱신된 (dirty) 데이터를 디스크로 강제로 내려보내고, 모든 쓰기들이 처리되면 fsync() 루틴은 리턴한다
fsync() 가 리턴하면 응용 프로그램은 데이터가 영속성을 갖게 되었다는 것을 보장받기 때문에 안전하게 다음으로 진행할 수 있다
하지만 파일이 존재하는 디렉토리도 fsync() 해주어야 한다, 특히 파일이 새로 생성된 경우 디렉토리를 반드시 fsync() 해주어야 한다
+ 디렉토리도 해줘야 경로를 찾을 수 있다고 한다, 택배 보낼 건데 주소가 없는거지
39.8 파일 이름 변경
mv 는 rename (char *old, char *new) 라는 시스템 콜을 호출한다, 각 인자는 원래의 파일 이름 (old) 과 새로운 이름 (new) 이다
rename() 은 시스템 크래시에 대해 원자적으로 구현되어, 이름 변경 중 시스템 크래시가 발생하면 파일 이름은 중간 상태 없이 원래 이름이나 새로운 이름, 둘 중 하나의 이름을 가지게 된다
파일 이름 변경 시에 편집기는 1) 새로운 버전의 파일을 쓰고 2) fsync() 로 디스크에 기록한 후에 3) 새로운 파일의 메타데이터와 내용이 디스크에 기록되었다는 것을 확인하면 4) 임시 파일 이름을 원래 파일 이름으로 변경한다 5) 이전 버전의 파일을 삭제하고 동시에 새 파일로 교체하는 작업을 원자적으로 수행한다
🐣 원본을 납두고 갱신본을 업데이트한 다음에 갱신본 작업이 다 완료된 이후 교체하기 때문에 원자성이 보존된다 🐣
39.9 파일 정보 추출
파일 시스템은 각 파일에 대한 정보를 보관하고, 파일에 대한 정보를 메타데이터 metadata 라고 부른다
어떤 파일의 메타데이터를 보려면 stat() 이나 fstat() 시스템 콜을 사용하고, 인자는 파일에 대한 경로명 (또는 파일 디스크립터) 이다
/* stat 구조체 */
struct stat {
dev_t st_dev; // 파일이 저장된 장치의 ID
ino_t st_inol // 아이노드 번호
mode_t st_mode; // 보호
nlink_t st_nlink; // 하드링크의 수
uid_t st_uid; // 소유자의 사용자 ID
gid_t st_gid; // 소유자의 그룹 ID
dev_t st_rdev; // 장치 ID (특수 파일인 경우)
off_t st_size; // 총 크기, byte 단위
blksize_t st_blksize; // 파일 시스템 입출력의 블럭 크기
blkcnt_t st_blocks; // 할당된 블럭의 수
time_t st_atime; // 최종 접근 시간
time_t st_mtime; // 최종 갱신 시간
time_t st_ctime; // 최종 상태 변경 시간
};일반적으로 파일 시스템은 아이노드에 이 정보를 보관하고, 모든 아이노드는 디스크에 저장되어 있다
39.10 파일 삭제
파일은 rm 프로그램을 이용하여 삭제할 수 있다, strace 로 rm 을 확인해 보면 unlink() 라는 시스템 콜을 사용한다
unlink() 는 지워야 하는 파일 이름을 인자로 받은 후에 성공하면 0 을 리턴한다
왜 remove(제거) 나 delete (삭제) 가 아니라, unlink() 로 지우는지는 디렉터리에 대해서도 이해해야 한다
🐣 unlink()가 하는일
- 디렉터리에서 파일 이름을 제거한다.
- inode와 데이터 블록은 남아있어서 만약 이 파일을 참조하는 열린 파일 디스크립터가 있으면 실제 데이터는 지워지지 않는다.
'크래프톤정글 > 운영체제' 카테고리의 다른 글
| [OSTEP][영속성] CH40 파일 시스템 구현 (3) | 2024.11.27 |
|---|---|
| [OSTEP][영속성] CH39 파일과 디렉터리 #2 (2) | 2024.11.25 |
| [OSTEP] CH38 Redundant Array of Inexpensive Disk, RAID (0) | 2024.11.22 |
| [OSTEP][영속성] CH35 대화 + CH36 I/O 장치 (0) | 2024.11.17 |
| [OSTEP][가상화] CH23 완전한 가상 메모리 시스템 +대화 (1) | 2024.11.15 |