CH09 가상메모리
9.9 동적 메모리 할당
추가적인 가상메모리를 런타임에 획득할 필요가 있을 때, 동적 메모리 할당기를 사용하는 것이 좀 더 편리하고 호환성이 좋다
-> 프로그램이 실행되는 도중에 추가적인 가상메모리가 필요해질 경우, 동적 메모리 할당기를 사용하는 것이 더 좋다
동적 메모리 할당기는 힙 Heap 이라고 하는 프로세스의 가상메모리 영역을 관리한다
힙은 일반화의 오류를 범하지 않는 한도에서 힙이 미초기화된 데이터 영역 직후에 시작해서
위쪽으로 (높은 주소 방향으로) 커지는 무요구 메모리 영역이라고 가정한다
각각의 프로세스에 대해서, 커널은 힙의 꼭대기를 가리키는 변수 brk ("break" 라고 발음한다) 를 사용한다
할당기는 힙을 다양한 크기의 블록들의 집합으로 관리한다, 각 블록은 할당되었거나 가용한 가상메모리의 연속적인 묶음이고
할당된 블록은 응용하기 위해 명시적으로 보존되고, 가용한 free 블록은 할당을 위해 사용할 수 있다
할당된 블록은 메모리 할당기 자신에 의해 묵시적으로 반환될 때까지 할당된 채로 남아 있다

할당기들은 두 개의 기본 유형이 가능하다, 두 유형 모두 응용이 명시적으로 블록을 할당하도록 요구한다
어떤 엔트리가 할당된 블록을 반환하기 위해서 무엇이 사용되어야 하는지에 대해서 차이가 난다
1) 명시적인 할당기는 응용이 명시적으로 할당된 블록을 반환해 줄 것을 요구한다
ex. C 표준 라이브러리는 malloc 패키지를 제공한다, malloc 함수를 호출해서 블록을 할당하며,
free 함수를 호출해서 블록을 반환한다, C++ 에서 new 와 delete 호출이 유사하다
2) 묵시적 할당기들은 언제 할당된 블록이 더 이상 프로그램에 의해 사용되지 않고 블록을 반환하는지를 할당기가 검출할 수 있을 것을 요구한다
묵시적 할당기는 가비지 컬렉터 Garbage Collector 라고 알려져 있으며, 자동으로 사용하지 않은 할당된 블록을 반환시켜주는 작업을 가비지 컬렉션이라고 부른다 ex. List, ML, 자바 같은 상위수준 언어들은 할당된 블록들을 반환시키기 위해 가비지 컬렉션을 사용한다
9.9.1 malloc 함수와 free 함수
프로그램은 malloc 함수를 호출해서 힙으로부터 블록들을 할당받는다
#include <stdlib.h>
void *malloc(size_t size);
// Returns: pointer to allocated block if OK, NULL on error
malloc 함수는 블록 내에 포함될 수 있는 어떤 종류의 데이터 객체에 대해서 적절히 정렬된 최소 size 바이트를 갖는 메모리 블록의 포인터를 리턴한다, 만일 malloc 이 메모리 할당에 실패하면 NULL 을 리턴하고, 시스템 오류를 나타내는 errno 를 설정한다
malloc 은 리턴하는 메모리를 초기화하지 않는다
초기화된 동적 메모리를 원하는 응용들은 calloc 을 사용할 수 있는데, 이것은 할당된 메모리를 0으로 초기화하는 calloc 함수 주위의 얇은 래퍼 함수다
이전에 할당된 블록의 크기를 변경하려는 응용은 realloc 함수를 사용할 수 있다
-> malloc 함수는 요청된 크기만큼의 메모리 블록을 할당하고 그 메모리 블록의 시작 주소를 포인터로 반환한다, 할당된 메모리 블록은 특정한 데이터 형식에 대해 올바르게 정렬되며, 최소 size 바이트 크기를 갖는다, 할당된 메모리를 초기화하지 않아 초기 상태는 예측할 수 없다
calloc 은 malloc 과 달리 할당된 메모리를 0으로 초기화하는 기능이 추가된 함수이고
이전에 할당된 메모리의 크기를 조정하려는 경우에는 realloc 함수를 사용하면 된다, realloc 은 기존 메모리 블록의 크기를 변경하고, 필요할 경우 새로운 메모리 블록을 할당한 후 그 내용을 복사한다
malloc 같은 동적 메모리 할당기는 mmap 과 munmap 함수를 사용해서 명시적으로 힙 메모리를 할당하거나 반환하며, 또는 sbrk 함수를 사용할 수 있다
#include <unistd.h>
void *sbrk(intptr_t incr);
// Returns; old brk pointer on success, -1 on error
sbrk 함수는 커널의 brk 포인터에 incr 을 더해서 힙을 늘리거나 줄인다
성공한다면 이전의 brk 값을 리턴하고, 아니면 -1을 리턴하고 errno 을 ENOMEM 으로 설정한다
만일 incr 이 0이 아니면 sbrk 는 현재의 brk 값을 리턴한다
프로그램들은 free 함수를 호출해서 할당된 힙 블록을 반환한다
#include <stdlib.h>
void free (void *ptr);
// Returns: nothing
ptr 인자는 malloc, calloc, realloc 에서 획득한 할당된 메모리 블록의 시작을 가리켜야 한다
그렇지 않다면 free 의 동작은 정의되지 않으며, free 는 아무것도 리턴하지 않기 때문에 free 는 뭔가 잘못되었다는 것을 알릴 수 없다
C 프로그램에서 16워드의 (매우) 작은 힙을 malloc과 free가 어떻게 관리할 수 있는지를 보여준다

그림 a) 프로그램은 4워드 블록을 요청한다, malloc은 가용 블록의 앞 부분에서 4워드 블록을 잘라내고, 이 블록의 첫번째 워드를 가리키는 포인터를 리턴한다
그림 b) 프로그램은 5워드 블록을 요청한다, malloc은 가용 블록의 앞부분에서 6블록을 할당한다 (가용 블록이 더블 워드 경계에 정렬되도록 하기 위해 블록에 추가적인 워드를 패딩하였다)
그림 c) 프로그램은 6워드 블록을 요청하고, malloc은 가용 블록에서 6워드 블록을 잘라낸다
그림 d) 프로그램은 b 에서 할당된 6워드 블록을 반환해준다, free로의 호출이 리턴한 후에도 포인터 p2는 여전히 malloc 된 블록을 가리킨다, p2가 새로운 malloc 콜에 의해 다시 초기화될 때까지 p2를 사용하지 않는 것은 응용의 책임이다
그림 e) 프로그램은 2워드 블록을 요청한다, 이 경우에 malloc은 이전 단계에서 반환된 블록의 부분을 할당하고, 이 새로운 블록의 포인터를 리턴한다
9.9.2 왜 동적 메모리 할당인가?
프로그램들이 동적 메모리 할당을 사용하는 가장 중요한 이유는 종종 이들이 프로그램을 실제 실행시키기 전에는 자료 구조의 크기를 알 수 없는 경우들이 있기 때문이다, 고정된 배열 크기가 있다는 것은 수백만 라인의 코드와 수많은 사용자가 있는 큰 규모의 소프트웨어 제품에서는 관리하는 데 어려움이 될 수 있다
더 나은 방법은 n 값을 알 수 있을 때 배열을 런타임에 동적으로 할당하는 것이며, 이 방법으로 배열의 최대 크기는 가용한 가상메모리의 양에 의해서만 제한된다


9.9.3 할당기 요구사항과 목표
명시적 할당기들은 다소 엄격한 제한사항 내에서 동작해야 한다
1. 임의의 요청 순서 처리하기 - 할당 요청과 반환 요청은 특정한 순서 없이 임의로 발생할 수 있으므로 할당기는 메모리 블록들이 적절히 관리되고 잘못된 접근이나 이중 반환 등의 오류가 발생하지 않도록 해야 한다
2. 요청에 즉시 응답하기 - 할당기는 메모리 할당 요청이 들어왔을 때 지체 없이 즉시 응답할 수 있어야 한다
3. 힙만 사용하기 - 확장성을 갖기 위해서 할당기가 사용하는 비확장성 자료 구조들은 확장성 자료 구조 힙 자체에 저장되어야 한다
4. 블록 정렬하기 (정렬 요건) - 할당기는 블록들이 어떤 종류의 데이터 객체라도 저장할 수 있도록 하는 방식으로 정렬해야 한다
5. 할당된 블록을 수정하지 않기 - 할당기는 가용 블록을 조작하거나 변경할 수만 있다, 일단 블록이 할당되면 이들을 수정하거나 이동하지 않는다, 그래서 할당된 블록들을 압축하는 것 같은 기법들은 허용되지 않는다
할당기 개발자는 이러한 제한사항들을 가지고 작업하기 위해서 처리량과 메모리 이용도를 최대화하려는 종종 상충되는 성능 목표를 달성하기 위해 노력한다
목표 1. 처리량 극대화하기
n번의 할당과 반환 요청의 배열이 주어졌을 떄 할당기의 처리량을 최대화하려고 하며, 이것은 단위 시간 당 완료되는 요청의 수로 정의된다
할당 요청의 최악 실행 시간이 가용 블록의 수에 비례하고, 반환 요청의 실행 시간이 상수인 적당히 좋은 성능의 할당기를 만드는 것은 그리 어렵지 않다
목표 2. 메모리 이용도를 최대화하기
한 시스템에서 모든 프로세스에 의해 할당된 가상메모리의 양은 디스크 내의 스왑 공간의 양에 의해 제한된다
할당기가 힙을 얼마나 효율적으로 사용하는지를 규정하는 방법 중에 가장 유용한 단위는 최고 이용도 Peak Utilization 이다
특히, 힙 이용도를 희생해서 처리량을 최대화하는 할당기를 작성하는 것은 쉽다
9.9.4 단편화 Framentation
단편화는 나쁜 힙 이용도의 주요 이유로, 가용 메모리가 할당 요청을 만족시키기에는 가용하지 않았을 때 일어난다 (추가 공부)
1) 내부 단편화 - 할당된 블록이 데이터 자체보다 더 클 때 일어난다
내부 단편화는 정량화하기가 간단하다, 단순히 할당된 블록의 크기와 이들의 데이터 사이의 차이의 합이라 시간 상 어디서든 내부 단편화의 양은 이전에 요청한 패턴과 할당기 구현에만 의존한다
2) 외부 단편화 - 할당 요청을 만족시킬 수 있는 메모리 공간이 전체적으로 공간을 모았을 때는 충분한 크기가 존재하지만, 이 요청을 처리할 수 있는 단일한 가용 블록은 없는 경우에 발생한다
외부 단편화는 내부 단편화보다는 훨씬 더 측정하기 어려운데, 그것은 이전 요청의 패턴과 할당기 구현 뿐 아니라
미래의 요청 패턴에도 의존하기 때문이다, 그렇기 때문에 할당기들은 더 적은 수의 더 큰 가용 블록들을 유지하려는 방법을 채택하고 있다
9.9.5 구현 이슈
처리량과 이용도 사이에 좋은 균형을 찾는 실용적인 할당기는 다음 이슈들을 고려해야 한다
가용 블록 구성 - 어떻게 가용 블록을 지속적으로 추적하는가?
배치 - 새롭게 할당된 블록을 배치하기 위한 가용 블록을 어떻게 선택하는가?
분할 - 새롭게 할당한 블록을 가용 블록에 배치한 후 가용 블록의 나머지 부분들로 무엇을 할 것인가?
연결 - 방금 반환된 블록으로 무엇을 할 것인가?
9.9.6 묵시적 가용 리스트 Explicit Free List
모든 실용적인 할당기는 블록 경계를 구분하고, 할당된 블록과 가용 블록을 구분하는 데이터 구조를 필요로 한다
대부분의 할당기는 이 정보를 블록 내에 내장하고, 이 경우에 한 블록은 1워드 헤더, 데이터, 추가적인 패딩으로 구성된다
헤더는 블록 크기 (헤더와 추가적인 패딩 포함) 와 블록이 할당되었는지 가용 상태인지를 인코딩한다

만일 더블 워드 정렬 제한 조건을 부과한다면 블록 크기는 항상 8의 배수이고, 블록 크기의 하위 3비트는 항상 0이다
+ malloc 으로 메모리 할당을 하게 되면 그 앞의 4 byte 는 헤더가 들어가고 메모리 블록의 크기와 가용 상태 내용이 들어간다
8의 배수인 경우인 이유는 8 1000, 16 10000, 24 11000 등으로 하위 3비트가 모두 0이기 때문에 사용 가능하다
메모리 블록의 크기 Header & 0xFFFFFFF8, 가용 상태 Header & 1
예를 들어, 블록 크기 24바이트 (0x18) 를 갖는 할당된 블록과 40 (0x28) 바이트를 가용 블록의 헤더는 각각 아래와 같다


헤더 다음에는 응용이 malloc을 불렀을 때 요구한 데이터가 따라오고,
데이터 다음에는 사용하지 않은, 크기가 가변적인 패딩이 따라올 수 있다
패딩은 외부 단편화를 극복하기 위한 할당기 전략의 일부분일 수도 있고 정렬 요구사항을 만족하기 위해 필요할 수도 있다
이러한 구조는 가용 블록이 헤더 내 필드에 의해 묵시적으로 연결되기 때문에 묵시적 리스트라고 부른다
할당기는 간접적으로 가용 블록 전체 집합을 힙 내의 전체 블록을 다니면서 방문할 수 있다
묵시적 가용 리스트의 장점은 단순성이다
중요한 단점은 할당된 블록을 배치하는 것과 같은 가용 리스트를 탐색해야 하는 연산들의 비용이
힙에 있는 전체 할당된 블록과 가용 블록의 수에 비례한다는 것이다
시스템의 정렬 요구 조건과 할당기의 블록 포맷 선택이 할당기에 최소 블록 크기를 결정한다
할당되거나 반환된 블록 모두는 이 최소값보다 더 작을 수 없다
9.9.7 할당된 블록의 배치
어플리케이션이 k 바이트의 블록을 요청할 때, 할당기는 요청한 블록을 저장하기에 충분히 큰 가용 블록을 리스트에서 검색한다
할당기가 이 검색을 수행하는 방법은 배치 정책에 의해서 결정되며, first fi t, next fit, best fit 이 주로 사용된다
First Fit 은 가용 Free 리스트를 처음부터 검색해서 크기가 맞는 첫 번째 가용 블록을 선택한다
장점은 리스트의 마지막에 가장 큰 가용 블록들을 남겨두는 경향이 있다는 점이고
단점은 리스트의 앞부분에 작은 가용 블록들을 남겨두는 경향이 있어서 큰 블록을 찾는 경우에 검색 시간이 늘어난다는 것이다
Next Fit 은 이전 검색이 종료된 지점에서 검색을 시작한다
First Fit 에 비해서 매우 빠른 속도를 갖는데, 리스트의 앞부분이 많은 작은 크기의 조각들로 구성되면 특히 더 이런 성향을 보인다
그렇지만 Next Fit 이 First Fit 보다 최악의 메모리 이용도를 갖는 것으로 밝혀졌다
Best Fit 은 모든 가용 블록을 검사하며 크기가 맞는 가장 작은 블록을 선택한다
일반적으로 First Fit 이나 Next Fit 보다는 더 좋은 메모리 이용도를 갖지만
단순한 가용 리스트 구성을 사용해서는 힙을 완전히 다 검색해야 한다는 단점이 있다
9.9.8 가용 블록의 분할
할당기가 크기가 맞는 가용 블록을 찾은 후에 가용 블록의 어느 정도를 할당할지에 대해 정책적 결정을 내려야 한다
이 가용 블록 전체를 사용하는 방법도 있지만, 큰 단점은 내부 단편화가 생긴다는 것이다, 만일 배치 정책으로 인해 크기가 잘 맞는다면 일부 추가적인 내부 단편화는 수용할 수도 있지만, 크기가 잘 안 맞는다면, 대게 할당된 블록과 새로운 가용 블록 영역, 두 영역으로 나눌 수 있다
그림 9.36 은 할당기가 그림 9.36의 8워드 가용 블록을 분할해서 응용이 요청한 3워드 힙 메모리 할당을 어떻게 만족시키는지 보여준다

9.9.9 추가적인 힙 메모리 획득하기
할당기가 요청한 블록을 찾을 수 없다면, 메모리에서 물리적으로 인접한 가용 블록들을 합쳐서 (연결해서) 더 큰 가용 블록을 만들어 볼 수 있다, 이렇게 해도 충분히 큰 블록이 만들어지지 않거나 가용 블록이 이미 최대로 연결되었 면
할당기는 커널에게 sork 함수를 호출해서 추가적인 힙 메모리를 요청한다, 할당기는 추가 메모리를 한 개의 더 큰 가용 블록으로 변환하고, 이 블록을 가용 리스트에 삽입한 후에 요청한 블록을 이 새로운 가용 블록에 배치된다
9.9.10 가용 블록 연결하기
할당기가 할당한 블록을 반환할 때, 새롭게 반환하는 블록에 인접한 다른 가용 블록들이 있을 수 있고
이러한 인접 가용 블록들은 오류 단편화 False Fragmentation 라는 현상을 유발할 수 있다
이때는 작고 사용할 수 없는 가용 블록으로 쪼개진 많은 가용 메모리들이 존재한다

오류 단편화를 극복하기 위해 실용적인 할당기라면 연결 Coalescing 이라는 과정으로 인접 가용 블록들을 통합해야 한다
이 과정에서는 언제 연결을 수행해야 할지에 관한 중요한 정책 결정을 해야한다
블록이 반환될 때마다 인접 블록을 통합해서 즉시 연결을 선택할 수 있고
일정 시간 후에 가용 블록들을 연결하기 위해 기다리는 지연 연결을 선택할 수도 있다
즉시 연결은 간단하며 상수 시간 내에 수행할 수 있지만, 일부 요청 패턴에 대해서는 블록이 연속적으로 연결되고 잠시 후에 분할되는 쓰래싱의 형태를 유발할 수 있다
9.9.11 경계 태그 연결하기
반환하려고 하는 블록을 현재 블록 Current Block 이라고 하면, 다음 가용 블록을 (메모리에서) 연결하는 것은 쉽고 효율적이다
현재 블록의 헤더는 다음 블록의 헤더를 가리키고 있으며, 다음 블록의 가용 여부를 확인할 수 있고, 블록은 상수 시간 내에 연결할 수 있다
그러나 이전 블록을 연결하고자 하는 상황에서 헤더를 사용하는 묵시적 가용 리스트가 주어진다면,
현재 블록에 도달할 때까지 전체 리스트를 검색해서 이전 블록의 위치를 기억하는 방법이 유일하다,
묵시적 가용 리스트를 사용하면, 이것은 각각의 Free 호출이 힙의 크기에 비례하는 시간을 소모할 것이라는 것을 의미한다
경계 태그라는 기법은 상수 시간 이전에 이전 블록을 연결하게 해준다,
각 블록의 끝 부분에 풋터 Footer (경계 태그) 를 추가하는 것으로, 이 푸터는 헤더를 복사한 것이다

할당기가 현재 블록을 반환할 때 가능한 모든 경우들에 대해 생각해보자
1. 이전과 다음 블록이 모두 할당되어 있다
2. 이전 블록은 할당 상태, 다음 블록은 가용 상태다
3. 이전 블록은 가용 상태, 다음 블록은 할당 상태다
4. 이전 블록과 다음 블록 모두 가용 상태다




Case 1은 인접 블록 모두가 할당 상태이고, 연결이 가능하기 때문에 현재 블록의 상태는 할당에서 가용으로 변경된다
Case 2에 서 현재 블록은 다음 블록과 통합된다, 현재 블록과 다음 블록의 푸터는 현재와 다음 블록의 크기를 합한 것으로 갱신된다
Case 3에서 이전 블록은 현재 블록과 통합되고, 이전 블록의 헤더와 현재 블록의 푸터는 두 블록의 크기를 합한 것으로 갱신된다
4번에서 세 블록 모두는 하나의 가용 블록으로 통합되고, 이전 블록의 헤더와 다음 블록의 푸터는 세 블록의 크기를 합한 것으로 갱신된다
각각의 경우에 연결은 상수 시간에 이루어진다
경계 태그 아이디어의 잠재적인 단점은, 각 블록이 헤더와 푸터를 유지해야 하므로,
만일 응용이 많은 작은 크기의 블록을 다룬다면 상당한 양의 메모리 오버헤드가 발생할 수 있다
(+ 데이터보다 관리 정보가 차지하는 비중이 크기 때문에 상당한 메모리 낭비가 발생할 수 있다)
현재 블록을 메모리에 있는 이전과 다음 블록과 연결하려고 할 때
이전 블록이 가용한 경우에만 이전 블록의 푸터에 있는 Size 필드가 필요하므로
현재 블록의 추가적인 하위 비트들 중 하나에 이전 블록의 할당/ 가용 비트를 저장하려고 한다면
할당된 블록들은 푸터가 필요 없어지고, 이 추가적인 공간을 데이터를 위해 사용할 수 있다
하지만, 가용 블록은 푸터가 필요하다는 점에 유의해야 한다
(+ 메모리 병합을 효율적으로 처리하기 위해 가용 블록에서 푸터가 중요한 역할을 하기 때문)
9.9.12 종합 설계 - 간단한 할당기의 구현
할당기 기본 설계
우리의 할당기는 memlib.c 패키지에서 제공되는 메모리 시스템의 모달을 사용한다
이 모델의 목적은 우리가 설계한 할당기가 기존의 시스템 수준의 malloc 패키지와 상관 없이 돌 수 있도록 하기 위한 것이다
mem_init 함수는 힙에 가용한 가상메모리를 큰 더블 워드로 정렬된 바이트의 배열로 모델한 것이다
mem_heap 과 mem_brk 사이의 바이트들은 할당된 가상메모리를 나타내며
mem_brk 다음에 오는 바이트들은 미할당 가상메모리를 나타낸다
할당기는 mem_sbrk 함수를 호출해서 추가적인 힙 메모리를 요청하며, 이것은 힙을 축소하라는 요청을 거부하는 것만 제외하고는
시스템의 sbrk 함수와 동일한 의미뿐만 아니라 동일한 인터페이스를 갖는다
할당기는 세 개의 함수를 응용프로그램에 알려준다


mm_init 함수는 할당기를 초기화하고, 성공이면 0을 아니면 -1을 리턴한다
mm_malloc과 mm_free 함수는 이들에 대응되는 시스템 함수들과 동일한 인터페이스와 의미를 가진다
할당기는 그림 9.39의 블록 포맷을 사용하며, 최소 블록 크기는 16바이트다
가용 리스트는 묵시적 가용 리스트로 구성되며 그림 9.42와 같은 변하지 않는 형태를 갖는다

첫번째 워드는 더블 워드 경계로 정렬된 미사용 패딩 워드이다, 패딩 다음에는 프롤로그 Prolog 블록이 오며,
이것은 헤더와 푸터로만 구성된 8바이트 할당 블록이다, 프롤로그 블록은 초기화 과정에서 생성되며 절대 반환하지 않는다
프롤로그 다음에는 malloc 또는 free를 호출해서 생성된 0 또는 1개 이상의 일반 블록들이 온다
힙은 항상 특별한 에필로그 Epiloque 블록으로 끝나며, 이것은 헤더만으로 구성된 크기가 0으로 할당된 블록이다
프롤로그와 에필로그 블록들은 연결 과정 동안에 가장자리 조건을 없애주기 위한 속임수다
할당기는 한 개의 정적 Static 변수를 사용하며, 이것은 항상 프롤로그 블록을 가리킨다
(작은 최적화로 프롤로그 블록 대신에 다음 블록을 가리키게 할 수 있다)
패딩 - 프롤로그 블록 - 일반 블록 - 에필로그 블록
가용 리스트 조작을 위한 기본 상수와 매크로

2-4번 줄은 기본 Size 상수 - 워드 크기 WDIZE, 더블 워드 DSIZE, 초기 가용 블록과 힙 확장을 위한 기본 크기 CHUNKSIZE
9번 줄부터 끝까지는 가용 리스트에 접근하고 방문하는 작은 매크로들이다
PACK 매크로 (9번 줄) - 크기와 할당 비트를 통합해서 헤더와 푸터에 저장할 수 있는 값 리턴
GET 매크로 (12번 줄) - 인자 p 가 참조하는 워드를 읽어서 리턴, 여기서 캐스팅이 매우 중요하다
인자 p 는 대게 (void*) 포인터이며, 이것은 직접적으로 역참조할 수는 없다
PUT 매크로 (13번 줄) - 각각 주소 p 에 있는 헤더 또는 푸터의 size 와 할당 비트 리턴
블록 포인터 bp 가 주어지면, HDRP와 FTRP 매크로는 각각 블록 헤더와 푸터를 가리키는 포인터를 리턴한다
NEXT_BLKP와 PREV-BLKP 매크로는 다음과 이전 블록의 블록 포인터를 각각 리턴한다
현재 블록의 포인터 bp가 주어지면, 다음과 같은 코드를 사용해서 메모리 내 다음 블록의 크기를 결정할 수 있다
size_t size = GET_SIZE(HDRP)NEXT_BLKP(bp)));초기 가용 리스트 만들기
mm_malloc 이나 mm_free 함수를 호출하기 전에 어플리케이션은 mm_init 함수를 호출해서 (그림 9.44) 힙을 초기화해야 한다

mm_init 함수는 메모리 시스템에서 4워드를 가져와서 빈 가용 리스트 (4~10번 줄) 를 만들 수 있도록 이들을 초기화한다
그 후에 extend_heap 함수 (그림 9.45) 를 호출해서 힙을 CHUNKSIZE 바이트로 확장하고 초기 가용 블록을 생성한다
extend_heap 함수는 두 가지 다른 경우에 호출된다 1) 힙이 초기화될 때 2) mm_malloc 이 적당한 맞춤 fit 을 찾지 못 했을 때
정렬을 유지하기 위해서 extend_heap 은 요청한 크기를 인접 2워드의 배수 (8바이트) 로 반올림하며
그 후에 메모리 시스템으로부터 추가적인 힙 공간을 요청한다 (7-9번 줄)
힙은 더블 워드 경계에서 시작하고, extend_heap으로 가는 호출은 그 크기가 더블 워드의 배수인 블록을 리턴한다
따라서 mem_sbrk로의 모든 호출은 에필로그 블록의 헤더에 곧이어서 더블 워드 정렬된 메모리 블록을 리턴한다
헤더 (12번 줄) 는 새 가용 블록의 헤더가 되고, 이 블록의 마지막 워드는 새 에필로그 블록 헤더가 된다 (14번 줄)
마지막으로 이전 힙이 가용 블록으로 끝났다면, 두 개의 가용 블록을 통합하기 위해 colaesce 함수를 호출하고
통합된 블록의 블록 포인터를 리턴한다 (17번 줄)

블록 반환과 연결
응용은 이전에 할당한 블록을 mm_free 함수를 호출해서 반환하며, 이것은 요청한 블록을 반환하고 (반환된 블록 bp),
인접 가용 블록들을 9.9.11절에서 설명한 경계 태그 연결 기술을 사용해서 통합한다
coalesce 협조 함수의 코드는 그림 9.40 에서 요약한 네 경우의 직접적인 구현 결과이다
프롤로그와 에필로그 블록을 항상 할당으로 표시한 가용 리스트 포맷으로 인해
요청한 블록 bp가 힙의 시작 부분 또는 끝 부분에 위치하는 숨겨진 문제가 될 수 있는 경계 조건을 무시할 수 있게 된다
이들 특별 블록 없이는 코드는 더 복잡해지며, 에러가 생길 가능성이 높아지고 더 느려지는데
그 이유는 매 반환 요청에 대해서 드물게 발생하는 경계 조건들을 항상 체크해야 하기 때문이다

블록 할당
어플리케이션은 mm_malloc 함수를 호출해서 size 바이트의 메모리 블록을 요청한다
추가적인 요청들을 체ㅡ한 후에 할당기는 요청한 블록 크기를 조절해서 헤더와 푸터를 위한 공간을 확보하고 더블 워드 요건을 만족시킨다
12-13번 줄은 최소 16바이트 크기의 블록을 구성한다 (8바이트는 정렬 요건을 만족시키기 위해, 추가적인 8바이트는 헤더와 푸터 오버헤드를 위해, 8바이트는 정렬 요건을 만족시키기 위해, 추가적인 8바이트는 헤더와 푸터 오버헤드를 위해)
8바이트를 넘는 요청에 대해서 (15번 줄) 일반적인 규칙은 오버헤드 바이트를 추가하고, 인접 8의 배수로 반올림하는 것이다
18번 줄에서 할당기가 요청한 크기를 조정한 후에 적절한 가용 블록을 가용 리스트에서 검색한다
만일 맞는 블록을 찾으면 할당기는 요청한 블록을 배치하고, 옵션으로 초과 부분을 분할하고, 새롭게 할당한 블록을 리턴한다
24-26번 줄에서 맞는 블록을 찾지 못하면, 힙을 새로운 가용 블록으로 확장하고,
요청한 블록을 이 새 가용 블록에 배치하고, 필요한 경우에 블록을 분할하며 (27번 줄),
이후에 새롭게 할당한 블록의 포인터를 리턴한다

9.9.13 명시적 가용 리스트
묵시적 가용 리스트는 블록 할당 시간이 전체 힙 블록의 수에 비례하기 때문에 범용 할당기에는 적합하지 않다
더 좋은 방법은 가용 블록들을 일종의 명시적 자료 구조로 구성하는 것이다
가용 블록의 본체는 프로그램에서 필요하지 않기 때문에 (사용되지 않으니 필요하지 않다)
이 자료구조를 구현하는 포인터들은 가용 블록의 본체 내에 저장될 수 있다

이중 연결 리스트를 사용하면 First Fit 할당 시간을 전체 블록 수에 비례하는 것에서 가용 블록의 수에 비례하는 것으로 줄일 수 있다
블록을 반환하는 시간은 아래 접근법들에 의해 달라질 수 있다
1) 새롭게 반환한 블록들을 리스트의 시작 부분부터 삽입해서 LIFO 순으로 유지하는 방법
LIFO 순서와 first fit 배치 정책을 사용하면 블록의 반환은 상수 시간에 수행된다
경계 태그를 사용하면 연결도 상수 시간에 수행할 수 있다
2) 리스트를 주소 순으로 관리하는 방법
리스트 내 각 블록의 주소가 다음 블록의 주소보다 작다,
메모리 블록을 반환할 때 해당 블록을 찾기 위해 모든 블록을 순차적으로 검색해야 한다 (검색 시간이 O(n))
이 경우, LIFO 순서를 사용하는 것보다 first fit 방식이 메모리 이용도가 더 좋으며, best fit 방식과 비슷한 수준의 이용도를 가진다
명시적 리스트의 단점은 일반적으로 가용 블록들이 충분히 커서 모든 필요한 포인터 뿐만 아니라 헤더, 푸터까지 포함해야 한다는 점이다
그 결과, 최소 블록 크기가 커지고 잠재적인 내부 단편화 가능성이 증가한다
| 명시적 리스트 | 묵시적 리스트 | |
| 구조 | 각 블록이 다음 블록을 가리키는 포인터 포함 | 연속된 블록 상태 정보만 포함 |
| 장점 | 빠른 블록 반환 | 구조가 단순하여 관리 용이 |
| 효율적인 메모리 탐색 | 메모리 오버헤드 감소 | |
| 단점 | 메모리 오버헤드 증가 (헤더, 푸터, 포인터) | 느린 탐색 (전체 블록 순차 검사) |
| 내부 단편화 증가 | 반환된 블록 즉시 연결 불가 | |
| 최소 블록 크기 | 크다 (헤더, 푸터, 포인터 포함) | 작다 (헤더만 포함) |
| 사용 예 | 블록 반환과 탐색이 잦은 경우 | 구조가 간단한 메모리 관리 필요 시 |
9.9.14 분리 가용 리스트
분리 저장 장치 Segregated Storage 는 할당 시간을 줄이는 대표적인 방법으로
다수의 가용 리스트를 유지하며, 각 리스트는 거의 동일한 크기의 블록들을 저장한다
모든 가능한 블록 크기를 크기 클래스 Size Class 라고 하는 동일 클래스의 집합으로 분리하고
할당기가 크기 n의 블록이 필요하다면 적당한 가용 리스트를 검색한다
만일 크기가 맞는 블록을 찾을 수 없다면, 다음 리스트를 검색한다
간단한 분리 저장 장치
각 크기 클래스를 위한 가용 리스트는 간단한 분리 저장 장치로 동일한 크기의 블록들을 가지며
각각은 크기 클래스의 가장 큰 원소의 크기를 갖는다 (ex. 크기 클래스 [17~32] -> 가용 리스트는 크기 32의 블록)
어떤 주어진 크기의 블록을 할당하기 위해서 적절한 가용 리스트를 검색한다
만일 리스트가 비어 있지 않다면, 첫 번째 블록 전체를 할당한다
(이 방식은 가용 블록은 할당 요청을 만족시키기 위해 분할하지 않는다, 분리 맞춤 방식에서는 분할한다)
만익 리스트가 비어있다면, 1) 할당기는 운영체제로부터 추가적인 고정 크기의 메모리를 요청하고
2) 이를 동일한 크기의 블록으로 나누며 3) 블록들을 연결해서 새로운 가용 리스트를 만든다
4) 할당기는 블록을 반환할 때 단순히 이 블록을 해당 가용 리스트의 맨 앞에 삽입한다
이 방식의 장점은 1) 블록을 할당하고 반환하는 것이 모두 빠른 상수 시간 연산 2) 블록 당 오버헤드가 거의 없다
3) 할당된 한 개의 블록의 크기는 그 주소로부터 추정할 수 있다 4) 헤더에 할당/ 가용 태그, 헤더, 푸터가 필요하지 않다
5) 이중 연결하는 대신에 단일 연결만 해도 된다
블록 내에 필요한 필드는 각 가용 블록 내의 1워드 succ 포인터이며, 최소 블록 크기는 1워드가 된다
단점은, 단순한 분리 저장 장치는 내부와 외부 단편화에 취약하다는 점이다
내부 단편화는 가용 블록들이 분할되지 않기 때문에 발생할 수 있다
또한 일부 참조 패턴은 가용 블록들이 절대로 연결되지 않기 때문에 극단적인 외부 단편화를 유발할 수 있다
(+ 불규칙적인 크기의 메모리 할당과 해제가 반복되면 큰 크기의 연속된 메모리 블록을 할당하는 것이 어려워진다)
분리 맞춤
이 방식에서 할당기는 가용 리스트의 배열을 관리한다
각 가용 리스트는 크기 Size 클래스에 연관되며, 일종의 명시적 또는 묵시적 리스트로 구성된다
블록을 할당하기 위해서 요청된 크기 클래스를 결정하고, 크기가 맞는 블록을 위해 해당 가용 리스트를 first-fit 방식으로 검색한다
만일 블록을 찾으면 (선택적으로) 블록을 분할하고, 나머지를 적당한 가용 리스트에 삽입한다
만일 맞는 블록을 찾지 못하면, 다음 크기의 클래스를 위한 가용 리스트를 검색한다, 블록을 찾을 때까지 이 과정을 반복한다
할당할 수 있는 블록이 없을 경우, 운영체제에게 추가 메모리를 요청하여 새로운 메모리 공간이 제공되면
그 공간에서 필요한 만큼을 할당하고, 남는 메모리는 잘라서 다른 크기로 나눠 관리한다
힙의 특정 부분만 first-fit 방식으로 검색하여 검색 시간이 줄고 메모리 사용을 최적화하지만
전체 리스트를 검색하지 않기 때문에 best-fit 보다 효율성이 떨어질 수 있다
버디 시스템
버디 시스템 할당기는 2의 제곱 크기를 가지는 특수한 분리 맞춤 방식이다
2^m개의 워드를 갖는 힙이 주어지면, 각 블록의 크기가 2^k인 분리 가용 리스트를 운영하는 방식이다 (0<=k<=m)
+ 2^k 크기의 블록은 항상 같은 크기의 버디 블록을 갖는다, 이 짝 관계 덕분에 빠르게 블록을 병합/ 분할할 수 있다
블록 크기 2^k인 블록을 할당하려면, 크기 2^j (k <= j <= m) 인 첫번째 가용 블록을 찾는다
j=k이면 할당이 완료되지만, 그렇지 않다면 재귀적으로 블록을 절반씩 나누어 j=k 까지 블록을 분할한다
분할을 수행할 때, 각각의 나머지 절반 (버디) 은 해당 가용 리스트에 배치된다
블록 크기 2^k의 메모리를 반환할 때는, 그 블록과 짝을 이루는 버디이 가용 리스트에 있는지 확인하고
만약 버디 블록도 반환되어 가용 상태라면, 그 둘을 하나의 더 큰 블록으로 병합한다
이 과정을 반복하다가 짝을 이루는 버디가 이미 할당된 상태라면 병합을 멈추고, 그 때의 크기로 가용 리스트에 추가한다
버디 시스템 할당기의 중요한 장점은 빠른 검색과 연결이고
주요 단점은 블록 크기가 2의 제곱이라 상당한 내부 단편화를 유발할 수 있다는 것이다
버디 시스템 할당기는 범용 부하에 대해서는 부적당하지만, 블록 크기가 사전에 미리 2의 제곱으로 고정된 경우 효과적이다
9.10 가비지 컬렉션
응용은 C maloc 패키지 같은 명시적 할당기를 사용해서 malloc과 free를 호출해서 힙 블록을 할당하고 반환한다
할당한 블록들을 반환하지 않은 경우, 프로그램이 살아있는 동안 할당된 채로 남아 있어 힙 공간이 낭비된다
가비지 컬렉터 Garbage Collector 는 프로그램에서 사용하지 않는 블록들을 자동으로 반환하는 동적 저장장치 할당기다
이러한 블록들을 가비지 Garbage 라고 하고, 자동으로 힙 저장장치를 반납하는 과정을 가비지 컬렉션이라고 한다
가비지 컬렉션을 지원하는 시스템에서 응용프로그램은 명시적으로 힙 블록을 할당하지만, 명시적으로 이들을 반환하지 않는다
그리고 이건 지금 공부 안 해도 될 거 같아서 넘어가려고 한다
9.11 C 프로그램에서의 공통된 메모리 관련 버그
9.11.1 잘못된 포인터의 역참조

int*형 변수에 int형의 변수를 대입하려고 하면 대부분의 컴파일러에서는 위와 같이 이를 제지할 것이다
하지만 C언어에는 명시적 형변환이라는 기능이 있다, 이는 컴파일러에게 특정 데이터 타입을 다른 타입으로 해석하도록 지시하는 방법이다
명시적 형변환을 사용하면 강제로 int형인 val변수를 int*형으로 해석하게 만들수 있게 되는데 이를 사용하여 p에 val의 값을 넣게 되면 그 결과는 아래와 같이 나타난다


컴파일러는 더이상 오류를 발생시키지 않고 빌드도 무사히 잘 실행되는 것을 볼 수 있다
이때 p의 값을 보면 16진수로 64. 즉, val의 값을 주소로서 가지고 있는것을 확인할 수 있다, 당연히 포인터에는 어떤 주소던지 넣을 수 있지만 해당 포인터를 역참조하여 그 주소의 값을 가져 올때는 유효하지 않은 주소 영역에 접근하려고 하여 오류가 발생할 수 있다
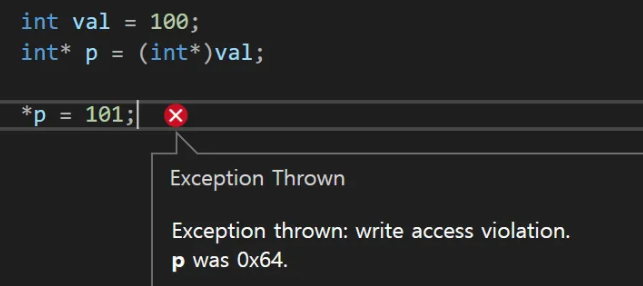
테스트를 위해서 visual studio에서 실행한 화면을 보면 쓰기 액세스 위반이라는 예외를 받은 것을 확인할 수 있는데, 이 쓰기(혹은 읽기) 액세스 위반은 5주차 RBTree의 테스트를 진행하면서 많이 볼 수 있는 Segmentation Fault와 같은 오류이다
다만 gcc의 Segmentation Fault는 오류를 굉장히 포괄적으로 알려주지만, visual studio에서는 오류의 세부 사항(읽기, 쓰기)를 알려준다는 차이점이 있다

포인터가 NULL을 가리키고 있을 때도 동일한 오류가 나타나는것을 볼 수 있다
위와 같이 액세스 위반을 하여 오류로 인해서 프로그램이 종료된다면 차라리 잘된 상황이라고 볼 수 있다, 만약 포인터에 잘못 들어간 어떤 값이 우연히도 주소로서 접근 가능한 공간일 경우 역참조해서 접근했을 때 사용자가 예측할 수 없는 동작을 일으킬 수 있기 때문이다

테스트를 위해서 통제가 가능한 값으로 넣어서 테스트를 진행해 보았다
int형 변수 b에는 int형 변수 a의 주소가 int타입으로 해석되어 들어가 있다
그리고 int형 변수 pi에는 int형 변수 b의 값이 int타입으로 해석되어 들어가게 된다


EFF900으로 a의 주소값임을 확인할 수 있다.
이는 접근이 유효한 메모리이기 때문에 int*형 변수 pi에 int형 변수인 b의 값이 들어갔지만
이 값을 통한 역참조 연산은 정상적으로 작동하는 것을 볼 수 있다.

9.11.2 초기화되지 않은 메모리를 읽는 경우

int*형 변수 y에 malloc함수를 사용하여 힙의 메모리를 4바이트만큼 할당해주었다
이 때 y를 초기화 해주지 않고 해당 주소의 값을 확인해보면

위와 같이 알 수 없는 값이 들어가 있는 것을 확인할 수 있다. 흔히 이런 값을 쓰레기값(Garbage Value)이라고 부른다
실제로 y가 가리키고 있는 주소를 확인해 보면 아래와 같은 값이 들어있는 것을 볼 수 있는데 위 값은 y를 역참조 연산으로 가져온 10진수 22778296를 16진수로 변환한 뒤, 뒤에서부터 2자리씩 읽은 값임을 계산을 통해 확인할 수 있다.
(뒤에서부터 두자리씩 읽으면 b8 91 5b (0)1이 된다, 이렇게 되어 있는 이유는 리틀엔디안, 빅엔디안 참조)


따라서 메모리를 할당한 뒤 초기화를 해주지 않으면 사용자가 원치 않는 동작을 할 수 있으니 메모리를 할당한 후에 바로 초기화 하는 것을 습관화 하는것이 좋다
9.11.6 포인터가 가리키는 객체 대신에 포인터 참조하기

위와 같은 코드가 있고 int*형인 p를 사용하여 a의 값을 바꾸고 싶을 때 *p--; 를 사용했다고 해보자
언뜻 보면 포인터 p를 역참조해서 그 값을 -1하는 코드로 보일 수 있지만 위 코드는 연산자 우선순위로 인해서 전혀 다른 동작을 보여준다
포인터의 역참조 연산자보다 후위 증감 연산자의 우선순위가 높기 때문에 의 코드는 포인터 p에 대한 -= 1 연산을 진행한 뒤 감소된 포인터에 대해 역참조 연산을 진행한다
위 코드를 visual studio에서 사용하면
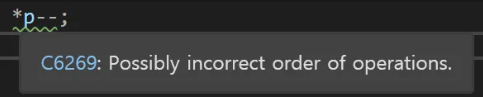
같은 경고를 내면서 역참조의 결과가 무시됨을 알리고 포인터가 처음에 역참조되는 이유에 대한 의문을 제기한다
따라서 위 코드를 원하는 의도대로 동작하도록 고치려면 아래와 같이 작성해야 한다
(*p)--;
실제로 잘못된 코드를 사용하면

a의 주소를 가리키고 있었을 p가 포인터에 -1연산을 하여 감소되어있는 것을 확인할 수 있다
그로 인해 역참조 연산 시 전혀 알 수 없는 값을 가져오는 것도 당연하다
9.11.7 포인터 연산에 대한 오해
책에도 나와있듯이 포인터에 대한 산술연산은 이들이 가리키는 객체의 크기 단위로 수행된다
int a;
int* pi = &a;
*pi = 0xABCDEF00;이와 같은 코드가 있다고 해보자
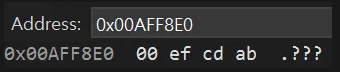
int a를 선언하고 int* pi에 a의 주소를 받아서 포인터 변수 pi를 통해서 a를 변경해 주고 있다
포인터 pi는 a의 주소를 가리키고 있고 해당 주소로 가보면 위에서 넣어준 0xABCDEF00이 연속된 메모리에 데이터를 저장하는 순서 규칙 중 리틀엔디안을 따라 거꾸로 저장되어 있는 것을 볼 수 있다

이제 위 주소를 아래 코드와 같이 사용한다고 해보자
short* ps = (short*)pi;
ps += 1;
*(ps) += 1;
먼저 short*형 변수 ps에 주소가 잘 들어갔는지 확인해보면 같은 주소를 가리키고 있는 것을 확인할 수 있다

그 후 ps += 1 연산을 통해 포인터에 산술 연산을 진행하면 책에서 말하는 대로 포인터가 가리키는 객체의 크기 단위(여기서는 short 2byte)로 연산이 되는것을 확인할 수 있다

이때 ps에 대해 역참조하여 가리키는 값에 + 1 연산을 해보면

이미 ps포인터를 가리키는 객체의 크기만큼(2바이트) 움직였기 때문에 0xABCDEF00 에 대해 +1 연산을 하는 것이 아닌 2바이트 뒤쪽인 0xABCD에 대해 +1 연산이 되는 것을 확인할 수 있다
(리틀엔디안으로 저장되어 있기 때문에 뒤쪽 2바이트에 AB CD가 저장되어있다, 물론 이것도 거꾸로)
9.11.8 존재하지 않는 변수 참조하기
이 상황을 만들어 내기 위해서 같은 크기의 스택을 만들어내는 두 함수를 선언해 보겠다
int* sum(int a, int b)
{
int sum = a + b;
return ∑
}
int* sub(int a, int b)
{
int sub = a - b;
return ⊂
}위 두 함수는 같은 타입과 같은 개수의 매개 변수를 받고 같은 타입과 같은 개수의 지역 변수를 선언하고 있기 때문에 같은 크기의 스택을 만들 것이다
실제로 두 함수가 호출되어 진입하는 부분을 디스어셈블리로 확인해보면


이와 같이 나오는데 위에서 보이는 sub esp, 8 부분이 진입한 함수의 스택을 할당한 부분이다
두 함수 모두 동일하게 8바이트의 스택을 할당 받은 것을 확인할 수 있다
정확한 스택포인터의 위치를 계산하기 위해서는 함수를 call하기 전 코드도 봐야하지만 여기서는 생략하겠다
처음 sum 함수를 호출한 뒤의 결과를 확인해보면


main으로 돌아와서도 결과값을 잘 가지고 있는 것을 확인할 수 있다
이는 sum 함수가 return을 하면서 스택을 정리하는 동작에 사용했던 스택메모리를 따로 다른 값으로 초기화하는 등의 동작이 없기 때문인데, 이 때문에 다른 함수가 호출되어 해당 메모리를 덮어 쓸 때까지는 정상값이 유지되는 것처럼 보일 것이다
이제 sum 함수 이후에 sub 함수를 호출 했을 때의 결과를 확인해 보겠다
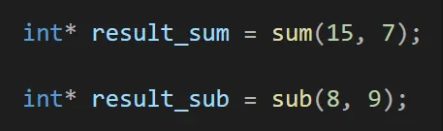

두 결과를 받는 포인터들이 같은 위치를 가리키고 있는 것을 확인할 수 있다
sum의 결과로 받은 주소는 sub를 실행하면서 덮어 씌워졌다는 것을 알 수 있다
때문에 함수에서 지역변수의 주소를 리턴하는 것은 유효하지 않은 메모리 주소를 가리킬 위험성이 매우 크기 때문에 하지 않아야 한다
9.11.9 가용 힙 블록 내 데이터 참조하기
int* x = (int*)malloc(sizeof(int);
*x = 0xaa;
free(x)
*x = 10;위와 같은 코드를 보면 할당한 메모리를 해제한 후에 해제된 메모리에 접근 하여 쓰기 작업을 하고 있기 때문에 잘못된 동작을 할거라는 예상이 된다. 그러면 구체적으로 어떤 문제가 생길까?
우선 첫 번째로 해당 메모리는 해제 되었지만 메모리가 있었던 힙의 메모리 페이지가 여전히 사용 가능할 경우, 접근하는데 액세스 위반은 하지 않았기 때문에 아무 문제가 생기지 않을 수 있다, 하지만 새로 메모리 할당을 할 때 해당 메모리가 다시 사용되었을 경우 접근해서 값을 바꾸면 사용자가 의도하지 않은 결과가 생길 수 있다


할당된 메모리를 해제하고 다시 접근하여 쓰기 작업을 해도 정상적으로 동작할 수 있다
두 번째 경우로는 메모리가 해제된 후 해제된 메모리가 있던 페이지도 Free 상태가 되어 사용할수 없게된 경우 다시 그 메모리에 접근하려고 하면 액세스 위반으로 에러가 발생할 것이다
두 경우 모두 매우 위험한 행위이므로 할당을 해제한 공간을 가리키는 포인터는 항상 NULL로 초기화 해주는 습관을 들이도록 하자
'크래프톤정글 > CS:APP' 카테고리의 다른 글
| [CS:APP] CH11 네트워크 프로그래밍 (0) | 2024.10.26 |
|---|---|
| CH06 메모리 계층구조 The Memory Hierarchy (0) | 2024.10.25 |
| CH07 링커 Linking (1) | 2024.10.14 |
| CH03 프로그램의 기계 수준 표현 3.6 (1) | 2024.10.01 |
| CH03 프로그램의 기계 수준 표현 3.1-3.5 (7) | 2024.09.27 |